ODIS: Object-level self-distillation
This post is about the lessons from building ODIS — Object-level Self-Distillation — a pretraining method for Vision Transformers that uses bounding boxes to improve representation quality. I’ll focus on what it took to make the system actually work: the architecture changes, the distributed training pitfalls, and the experiments that failed before the ones that succeeded. Paper conclusions are in the paper; what follows is the story behind them.
While the experiments in the paper use natural image benchmarks, the problem ODIS addresses (scenes containing multiple semantically distinct regions) shows up everywhere. It is especially acute in digital pathology, where a single image patch routinely contains multiple tissue types, cell populations, and morphological structures. That domain is a large part of why we think object-level pretraining matters beyond ImageNet numbers.
Background: self-distillation
DINO and iBOT train a vision transformer by running two augmented views of the same image through a student and a mean-teacher network, then minimising cross-entropy between their output probability vectors. The teacher is never backpropagated through, it’s updated as an exponential moving average of the student. The student learns a [CLS] token that summarises the full image, and in iBOT’s case, also learns to predict masked patches from unmasked context.
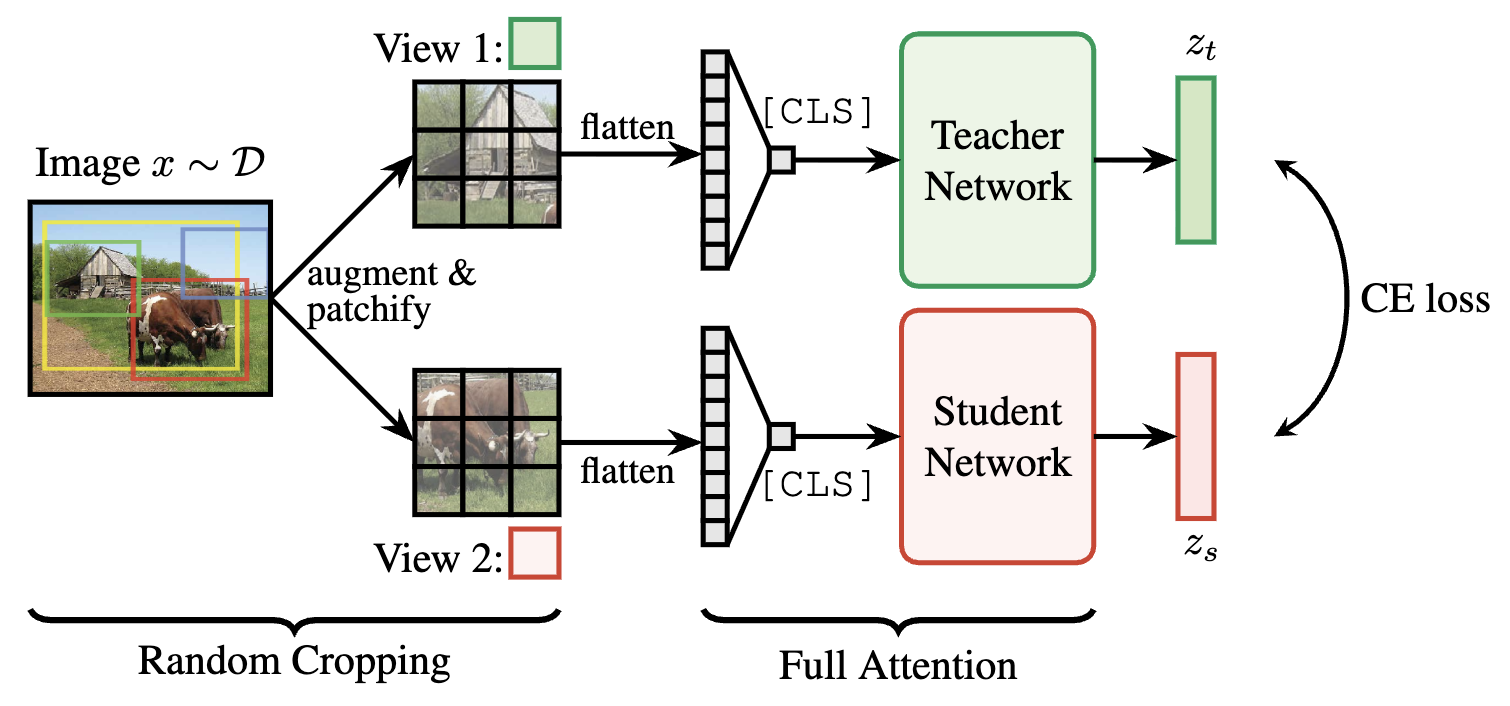
The key assumption is that different augmentations of the same image preserve the same semantic content. For more depth on DINO/iBOT, the original papers are the right place to start: DINO (Caron et al. 2021), iBOT (Zhou et al. 2021).
The problem: random crops break the shared-content assumption
The standard data augmentation pipeline includes random resized crop, colour jitter, flip, etc. They are fast to execute, agnostic to image size, and works well for datasets with central, salient objects. But it has a structural flaw: there is no mechanism to guarantee that the teacher and student receive crops containing the same object.
This matters more than it might seem. Roughly 20% of ImageNet-1K images contain objects from multiple distinct classes (Tsipras et al., 2020). Consider a typical barn scene like below: the teacher’s random crop lands on the ox while the student’s crop lands on the barn. The self-distillation loss now pushes the student’s “barn” representation towards matching the teacher’s “ox” representation. Hence, the supervision signal is often (slightly) wrong about everything in multi-object scenes.
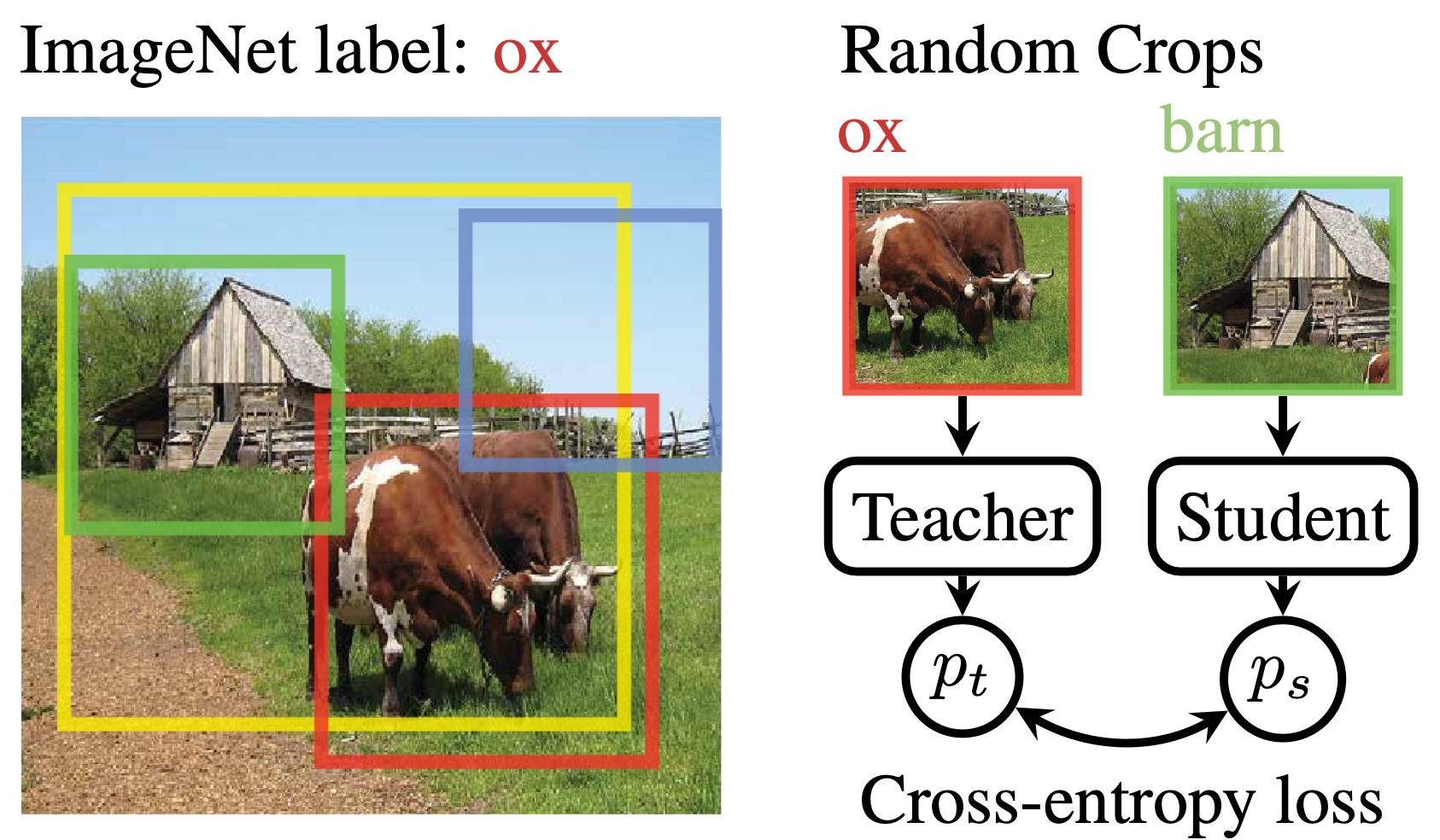
The fix is conceptually simple: tell both networks which object to look at. The challenge is doing this without breaking the things that make self-distillation work.
The solution: object-aware cropping + masked attention
ODIS replaces the [CLS] token, which summarises the whole image, with an [OBJ] token that summarises a specific object. Two mechanisms work together to make this token meaningful:
① Object-aware cropping ensures both teacher and student crops contain the target object. Concretely, for each image we sample a target bounding box, then resample random crops (up to 20 times each) until both crops contain the box. The object is then patchified into a binary mask indicating which patches fall inside the box. This is the primary driver of the improvement as it eliminates the inconsistent training signal at the source.
② Masked attention makes the [OBJ] token pool exclusively from patches that fall inside the bounding box, at every transformer layer. The [OBJ] token can only attend to object patches; patch tokens still attend to the full image unmasked (they need context). This yields a highly nonlinear, layer-wise object representation, which is very different from simply averaging patch embeddings inside the box.
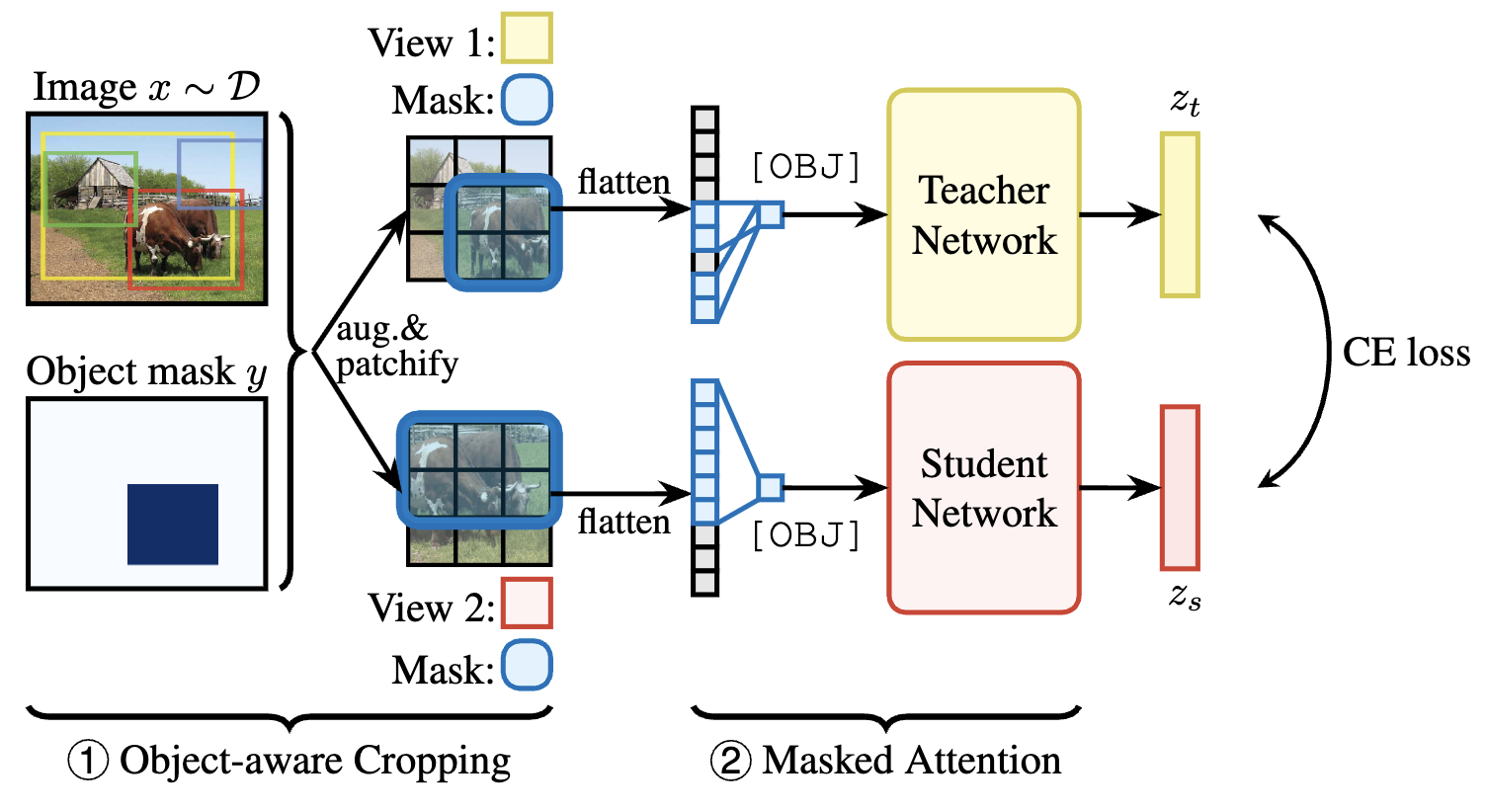
We perform an ablation verifying we need both. Only cropping images captures most of the gain but not all. Only masked-attention underperforms because the views are not aligned. Only together they provide clean alignment and clean aggregation.
Results: At the end, our approach improved the k-NN accuracy on ImageNet by +1.2% over iBOT (for context, the improvement from DINO to iBOT at ViT-B scale was +1.0 pp). This improvement grows with model scale. ODIS also transfers better to unseen datasets, which I find most practically significant. A model that generalises better across domains without any fine-tuning is a more useful backbone — the kind of thing that matters when deploying into a production system without dataset-specific fine-tuning for every new task.
Implementation deep-Dive: masked attention in the ViT
Just like causal masking in LLMs, the [OBJ] token attends to the all keys and values but its attention logits are masked: positions outside the bounding box get -inf before softmax, so they receive zero attention weight. This enables parallel computation of self-attention outputs at all positions. Importantly, this masking applies only to the [OBJ] row of the attention matrix, aka patch-to-patch attention is fully unmasked. Therefore, patches can still pull in context from background regions, which is important for building object representations that understand their surroundings.
The modification to the standard multi-head attention forward pass is straightforward:
def forward(self, x, obj_attn_mask=None):
B, N, C = x.shape # N = 1 (OBJ) + H*W (patches)
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads)
qkv = qkv.permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # [B, heads, N, head_dim]
attn = (q @ k.transpose(-2, -1)) * self.scale # [B, heads, N, N]
+ if obj_attn_mask is not None:
+ # obj_attn_mask: [B, H*W] binary, 1 = inside bounding box
+ # We want [OBJ] token (position 0) to attend only to in-box patches
+ # Patch positions start at index 1; prepend a 1 for the OBJ token itself
+ obj_mask_full = torch.cat(
+ [torch.ones(B, 1, device=x.device), obj_attn_mask.float()], dim=1
+ ) # [B, N]
+ # Broadcast to [B, heads, 1, N] — only the OBJ row is masked
+ mask_2d = (1 - obj_mask_full).bool()[:, None, None, :] # [B,1,1,N]
+ attn[:, :, 0:1, :] = attn[:, :, 0:1, :].masked_fill(mask_2d, float('-inf'))
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
return self.proj(x)
The computational overhead of this modification is ~1% (10:40 min/epoch for iBOT vs 10:48 for ODIS, on identical hardware). Most of that overhead comes from the object-aware view resampling, not the attention mask itself.
Implementation deep-dive: distributed training
ODIS uses data parallelism: the model is replicated on every GPU, and each copy processes a different shard of the batch. This is the right choice when the model fits in a single GPU’s memory, which ViT-S/B comfortably do. The alternative, model parallelism, splits the model itself across GPUs and is reserved for models too large to fit on one device, e.g., LLMs. Data parallelism is simpler and scales well, but it requires careful synchronization to keep replicas in agreement.
Two components are crucial in PyTorch implementation. The DistributedSampler ensures each GPU sees a disjoint slice of the dataset each epoch:
sampler = torch.utils.data.DistributedSampler(dataset, shuffle=True)
data_loader = torch.utils.data.DataLoader(dataset, sampler=sampler, ...)
DistributedDataParallel wraps the student, the module whose parameters are updated, and hooks into the backward pass to average gradients across GPUs via all_reduce before optimizer.step(). Under the hood, all_reduce is a ring operation: GPUs are arranged in a ring and exchange partial sums of the gradients with their neighbors in N-1 steps. One more round of exchange sends the globally averaged gradients to all GPUs. All happens with all GPUs talking to only two immediate neighbors:
student = nn.parallel.DistributedDataParallel(student, device_ids=[args.gpu])
...
loss.backward() # all_reduce happens here automatically
optimizer.step() # identical update on every GPU
The teacher is intentionally not DDP-wrapped. Instead, it lives as an independent copy on each GPU. This is fine since it has no gradients and is updated purely as an exponential moving avarage of the student:
# params_s and params_t are student and teacher parameters
with torch.no_grad():
m = momentum_schedule[it]
for param_s, param_t in zip(params_s, params_t):
param_t.data.mul_(m).add_((1 - m) * param_s.detach().data)
Since all GPUs apply this update to identical student parameters (kept in sync by DDP), the teacher copies naturally stay identical across GPUs without any explicit communication.
Important note: The one place where explicit distributed ops are needed is the loss centering. The teacher center, a running mean used to prevent representation collapse, must be consistent across GPUs, so it requires a manual all_reduce:
obj_center = torch.sum(teacher_obj, dim=0, keepdim=True)
dist.all_reduce(obj_center)
obj_center = obj_center / (len(teacher_obj) * dist.get_world_size())
self.center_obj = self.center_obj * self.center_momentum + obj_center * (1 - self.center_momentum)
Everything else (gradients, weights, EMA) stays in sync without any explicit collective operations.
What didn’t work
Our final method was shaped by the following three interesting failures:
Linear pooling of patch features. An obvious baseline for “object-level representation” is to follow Hénaff et al., 2021: just average the patch embeddings inside the bounding box, then apply the distillation loss to those pooled vectors. This was trivial to implement and collapsed badly: it averages 59.5% k-NN accuracy on ImageNet vs 72.7% for ODIS. Average pooling discards the nonlinear, layer-wise interaction structure that makes ViT representations powerful. This experiment was one of the most important validations that the masked-attention design is necessary, not just beneficial.
Blacking out background patches at inference. A natural inference-time augmentation is to zero out image patches that fall outside the bounding box — giving the network a “clean” view of just the object. We tried it and it consistently hurt performance for all models. The reason is that patch tokens use full unmasked self-attention: background context (barn walls, grass texture) helps patch tokens better represent the foreground object. Blacking out the background destroys this context and leads to weaker representations than either the standard full-image inference or masked-attention inference. For ODIS specifically, masked-attention inference (applying the box mask at the [OBJ] token position, same as training) is the right approach and gives the best results. For iBOT, object cropping works slightly better because iBOT was never trained with masked attention and can’t exploit it at inference time.
Multi-[OBJ] token collapse. The natural extension of ODIS is to introduce multiple [OBJ] tokens and distill several objects per image simultaneously. We tried 1, 2, and 4 [OBJ] tokens in preliminary 40-epoch runs on COCO. The results were counter-intuitive: more tokens led to worse results. We believe it is because the token representations were collapsing. This is inherent to non-contrastive distillation objectives: without an explicit loss promoting diversity, no force prevents two tokens from learning the same representation. Given the engineering complexity and the evidence that the single-token formulation already captures most of the gain, we made the pragmatic call to not pursue it further for this paper. It remains an open direction.
Where this goes
The core insight of ODIS is that utilizing consistent object-level targets during pretraining improves representation quality. This is not specific to iBOT-style distillation. The same object-aware cropping and masked-attention design could be applied to CLIP-style vision-language pretraining (align region features with the right text tokens), to masked autoencoder frameworks (predict masked object patches, not arbitrary patches), or to video pretraining (track objects across frames to enforce temporal consistency).
More practically, as foundation model APIs for bounding box extraction continue to improve (e.g., Grounding DINO, SAM variants), the cost of obtaining object annotations for arbitrary image datasets approaches zero. ODIS shows that even imperfect, class-agnostic boxes from off-the-shelf detectors produce measurable improvements over no boxes at all. Ground-truth boxes are better, but not required.
The takeaway for anyone building pretraining pipelines if bounding boxes are available, use them. The marginal gain increases with model scale, that’s a good trade-off.
Code and checkpoints will be released upon publication. Questions and feedback welcome.